介绍
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
主要功能
从一个URL,文件或字符串中解析HTML
使用DOM或CSS选择器来查找、取出数据
可操作HTML元素、属性、文本
常用方法
Jsoup.connect(url字符串).get()
从URL加载HTML
Jsoup.parse(HTML文件路径)
从文件加载HTML
Jsoup.parse(HTML字符串)
从字符串加载HTML
document.title()
获取HTML页面的标题
document.select()
获取标签
elements.attr()
获取标签的属性
引入依赖
1
2
3
4
5
| <dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
|
例子
Java代码
Link实体类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| package entity;
public class Link {
private Integer id;
private String linkName;
private String linkUrl;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getLinkName() {
return linkName;
}
public void setLinkName(String linkName) {
this.linkName = linkName;
}
public String getLinkUrl() {
return linkUrl;
}
public void setLinkUrl(String linkUrl) {
this.linkUrl = linkUrl;
}
}
|
测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import entity.Link;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Test {
public static void main(String[] args) throws Exception {
int i = 1;
List<Link> linkList = new ArrayList<>();
while (i <= 3) {
Document document = Jsoup.connect("http://www.zoutl.cn/index?page=" + i).get();
Elements links = document.select("a#div1");
for (Element link : links) {
Link link1 = new Link();
link1.setLinkName(link.text());
link1.setLinkUrl("http://www.zoutl.cn" + link.attr("href"));
linkList.add(link1);
}
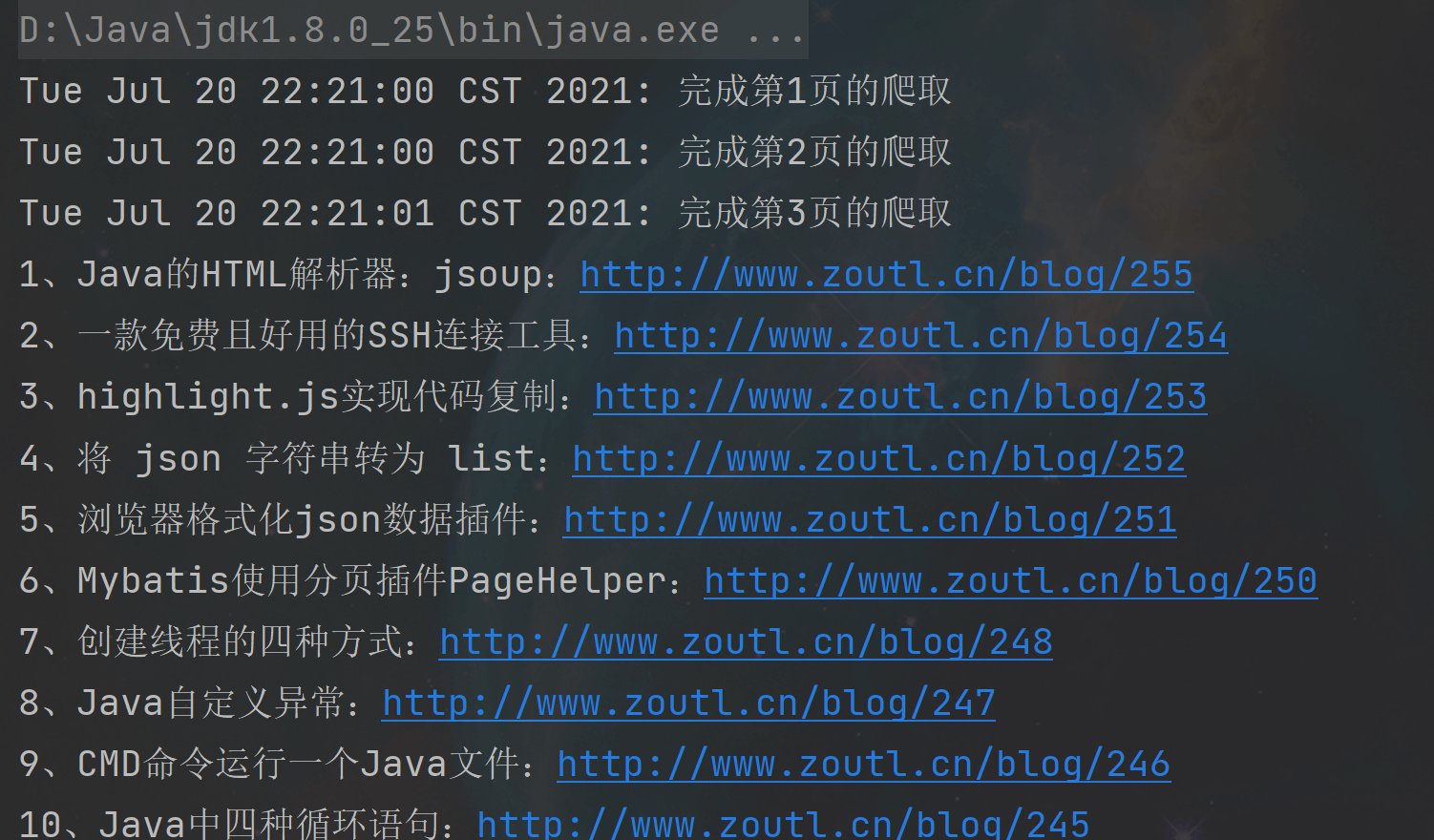
System.out.println(new Date() + ": 完成第" + i + "页的爬取");
i++;
}
int index = 1;
for (Link link : linkList) {
System.out.println(index + "、" + link.getLinkName() + ":" + link.getLinkUrl());
index++;
}
}
}
|
结果