概述
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前
算法描述
- 取得数组中的最大数,并取得位数
- arr为原始数组,从最低位开始取每个位组成radix数组
- 对radix进行计数排序(利用计数排序适用于小范围数的特点)
动图演示

算法实现
Java代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
public class Test {
public static void main(String[] args) {
int[] arr = {63, 157, 189, 51, 101, 47, 141, 121, 157, 156,194, 117, 98, 139, 67, 133, 181, 12, 28, 0, 109};
System.out.println("排序前:");
for (int i : arr) {
System.out.print(i+" ");
}
System.out.println();
radixSort(arr);
System.out.println("排序后:");
for (int i : arr) {
System.out.print(i+" ");
}
}
private static void radixSort(int[] arr) {
int max = arr[0];
int exp;
for (int anArr : arr) {
if (anArr > max) {
max = anArr;
}
}
for (exp = 1; max / exp > 0; exp *= 10) {
int[] temp = new int[arr.length];
int[] buckets = new int[10];
for (int value : arr) {
buckets[(value / exp) % 10]++;
}
for (int i = 1; i < 10; i++) {
buckets[i] += buckets[i - 1];
}
for (int i = arr.length - 1; i >= 0; i--) {
temp[buckets[(arr[i] / exp) % 10] - 1] = arr[i];
buckets[(arr[i] / exp) % 10]--;
}
System.arraycopy(temp, 0, arr, 0, arr.length);
}
}
}
|
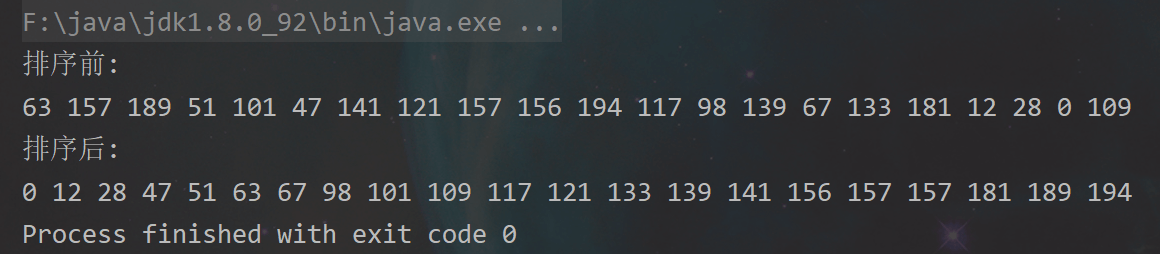
运行结果
算法分析
基数排序基于分别排序,分别收集,所以是稳定的。但基数排序的性能比桶排序要略差,每一次关键字的桶分配都需要O(n)的时间复杂度,而且分配之后得到新的关键字序列又需要O(n)的时间复杂度。假如待排数据可以分为d个关键字,则基数排序的时间复杂度将是O(d*2n) ,当然d要远远小于n,因此基本上还是线性级别的。基数排序的空间复杂度为O(n+k),其中k为桶的数量。一般来说n>>k,因此额外空间需要大概n个左右
PS.
搬运地址: 十大经典排序算法(动图演示) - 一像素 - 博客园 (cnblogs.com)










